-
파이썬 독학 7일차 BeautifulSoup(웹 파싱하기, 스크래핑) 2coding 2022. 9. 7. 00:00728x90반응형SMALL
6일차에 BeautifulSoup패키지를 인스톨하고 requests를 이용해 타겟 코드가 있는 사이트의 텍스트를 모조리 불러왔다.
전 포스팅에 이어 BeautifulSoup의 강력한 Method를 이용해 타겟 텍스트를 쉽게 찾아보겠다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
뷰티풀수프의 사이트에 보면 아래와 같이
soup.find_all("a", class_="sister")를 사용해주면
a링크 중 class가 sister인 텍스트를 모조리 찾아와 줄것이다.
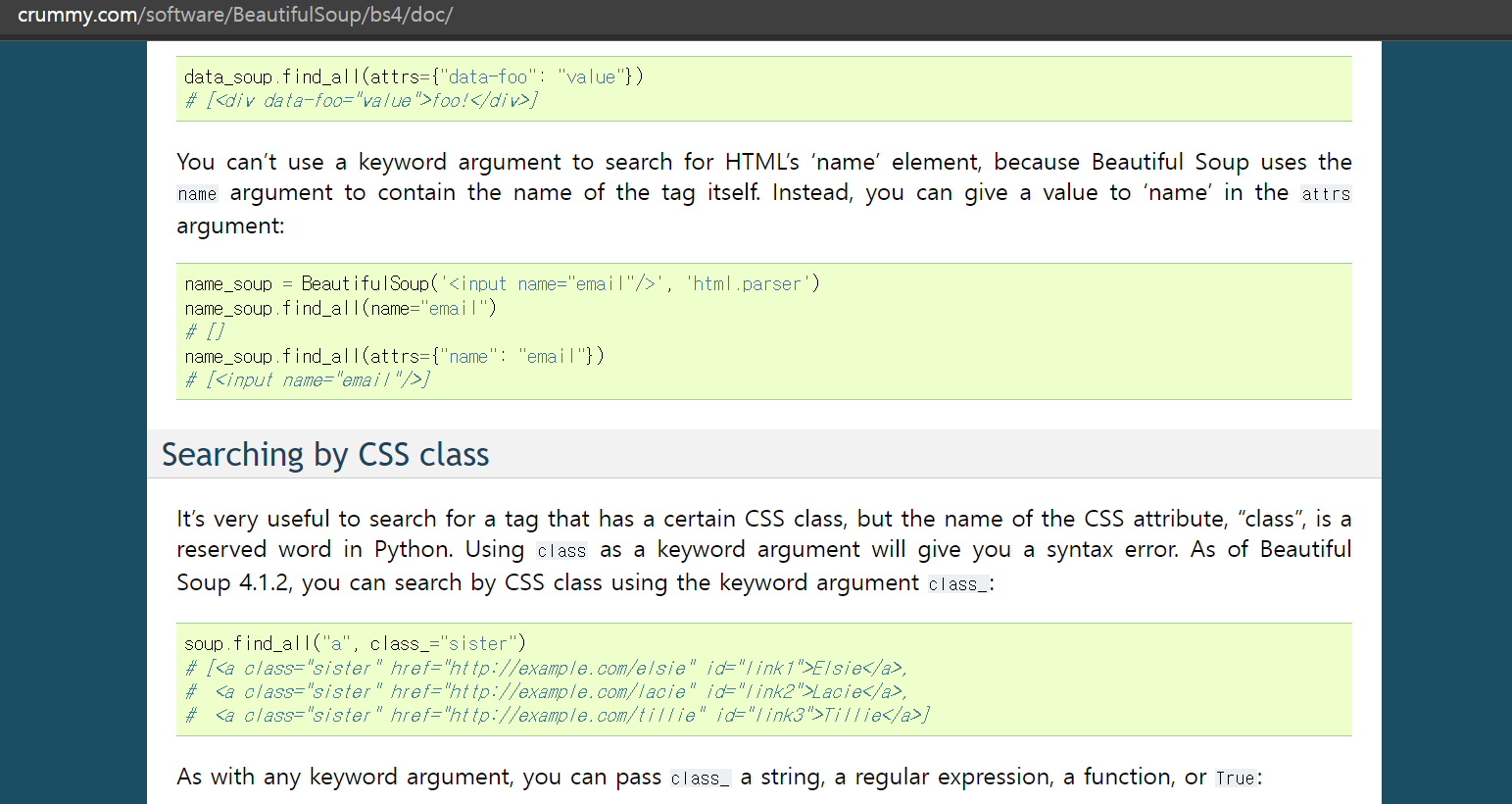
뷰티풀숲의 사용법은 아주 간단하다

1. from bs4 import BeautifulSoup을 통해 임포트해준 뒤
2. soup = BeautifulSoup(html_doc, 'html.parser')
첫번째 argument로 html_doc를 준 뒤 html.parser라는 문자열을 전해줘 html문서를 beautifulsoup에게 보내준다.
그렇다면 우리의 목표인 <section class="jobs">를 찾을 수 있을까?

위에 방법은 다 써놨으니 직접 해보는게 좋을것이다.
더보기#웹을 가져오기 위해 requests의 get을 임포트 from requests import get #beautifulsoup 사용을 위해 임포트 from bs4 import BeautifulSoup base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term=" search_term = "python" #나중에 url과 검색어를 변경하여 재사용할 수 있게 f문자열 포매팅 response = get(f"{base_url}+{search_term}") #웹사이트에서 정상적인 응답(200)을 주지 않을때를 대비 if not response.status_code == 200: print("Can't request website") #정상이라면 페이지의 html 코드를 쫙 긁어 옴 else: #print(response.text) soup = BeautifulSoup(response.text, 'html.parser') #위의 soup 코드를 통해 원하는 텍스트를 찾기 쉬워졌다 아래와 같이 코딩하자 jobs = print(soup.find_all('section', class_="jobs"))결과물
id="categort-2"의 jobs 클래스를 잘 불러왔고
검색했던대로 opencraft의 정보를 잘 파싱해왔다.
다음 포스팅에선 jobs 클래스 안의 list들을 묶어서 가져와보겠다.

 728x90반응형LIST
728x90반응형LIST'coding' 카테고리의 다른 글
파이썬 독학 9일차 BeautifulSoup(웹 파싱하기, 스크래핑) 3 (0) 2022.09.09 파이썬 독학 8일차 keyword argument 순서 상관없이 지정 (0) 2022.09.08 파이썬 독학 6일차 웹 스크래핑, 파싱(beautiful soup) 1 (0) 2022.09.06 파이썬 독학 5일차 pypi, requests 사용법 (0) 2022.09.05 파이썬 독학 4일차 (dicts) (0) 2022.09.04